We are making use of the Nitrokey HSM to issue leaf certificates for a PKI setup. For this we call openssl to work with the pkcs11 engine that can communicate with the HSM.
This works fine for the majority of time, but if we do a lot of requests in short succession, it seems that the key (or pcsd daemon?) gets into a state were it no longer can communicate, throwing a vague error:
Failed to enumerate slots
PKCS11_get_private_key returned NULL
Could not read CA private key from org.openssl.engine:pkcs11:0:10
40E7B621687F0000:error:41800005:PKCS#11 module:ERR_CKR_error:General Error:p11_slot.c:445:
40E7B621687F0000:error:40000067:pkcs11 engine:ERR_ENG_error:invalid parameter:eng_back.c:603:
40E7B621687F0000:error:13000080:engine routines:ENGINE_load_private_key:failed loading private key:../crypto/engine/eng_pkey.c:79:
The PCKS11/PKCS15 tools also fail to enumerate the devices at this point.
Did anyone on the forum encounter this before (or know a way how we can better debug this to find out what might be causing the problem)?
A full reboot + an replug of the Nitrokey HSM fixes the issue every time up to now, but that’s not a nice solution if we encounter this on a remote system…
We’re using the latest versions of libp11 (0.4.13) and opensc (0.26.1) to no avail (we upgraded from a previous version to be sure it wasn’t caused by a known bug).
Debug output came from running the PCSCD daemon with verbose logging and running the tools with debug verbosity.
I’ve seen something like this - during the attempt of the parallel use of the card, on in short succession, the card is “busy” and not available. Which PKCS#11 driver are you using?
The one from opensc: opensc-pkcs11.so; signing of certificates goes over OpenSSL commandline, and is normally not in parallel (but we do have a cron job requesting hsm info over the pkcs11-tool).
We are indeed seeing this happen every now and then when doing multiple requests in short time, but did not find a reproduction scenario yet where it can be triggered every time. As stated in the original post, the annoying thing is that if we get into this state, only a reboot and re-plug of the device seem to be working to bring it back to a normal state.
That’s why I’m inquiring on how I could possibly debug this so we can report an issue (or find a workaround)
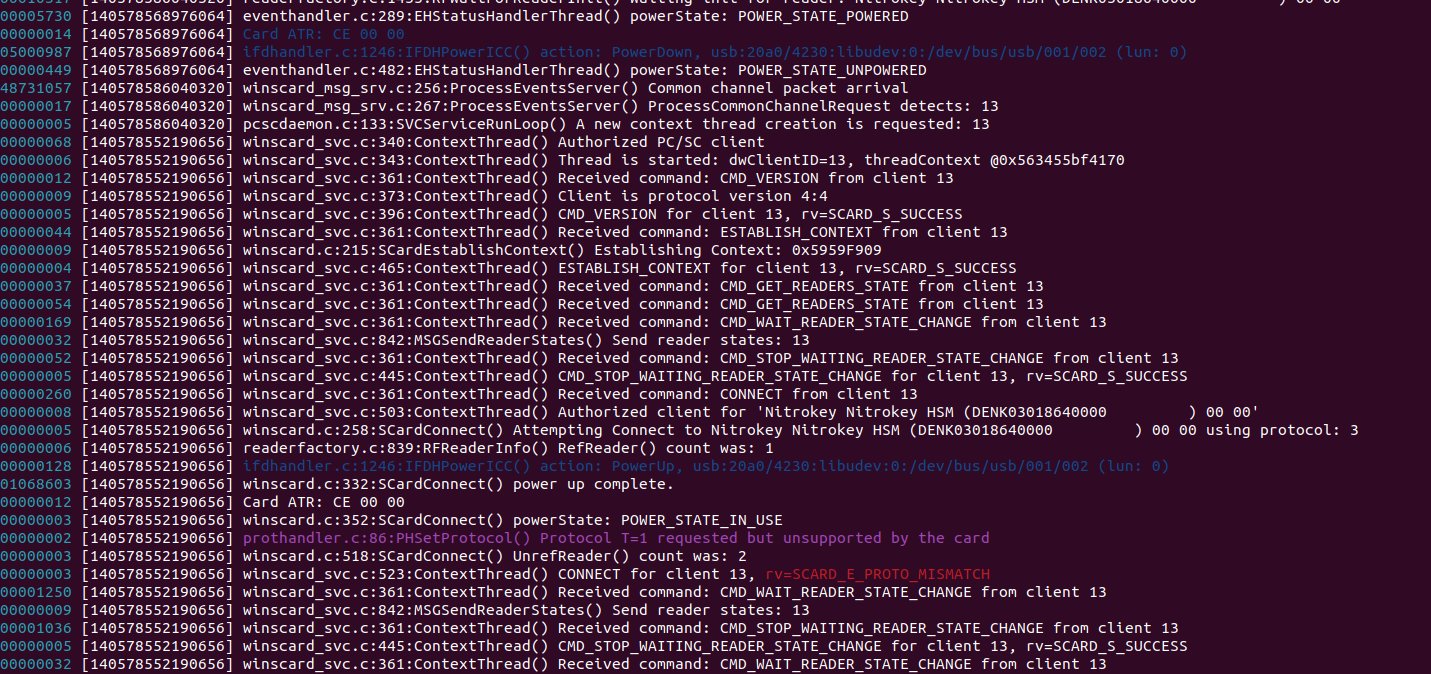
Card ATR CE 00 00 is certainly incorrect one. Maybe this is a leftover from the parallel operation. Maybe the card could not be reset fully or some other operation was running in parallel (like your cron check).
@saper After a couple of months of trying to reproduce it again with the opensc debug logs enabled (it really seems to be a race condition as it was stable for months with debug level 9 enabled…), I finally got a log trace. Given the file is quite big (~400mb) I tried to extract the useful section (to me I can’t really see why it’d fail), but if needed I can share the full one in private.
Personally I don’t see what’s going wrong here; the session before it starts acting up is seemingly closed perfectly fine.
Line 0-555 are an ongoing session to sign, which is seemingly handled correctly.
Line 556 and further a new context is set up, but then it doesn’t recognize the card anymore, followed by a long session of trying.
Line 4602 it sets another context (new call), but in this session it fails to connect to the card (-1100 (Generic reader error))